스레드 우선 순위(Thread Priority)
윈도우 스케줄러는 상대적인 우선순위에 따라서 스레드를 스케줄링한다. 이러한 우선 순위의 종류가 <표 1>에 나와 있다. 의미를 살펴보면 마치 말장난같이 적혀 있지만 해당 상수가 의미하는 정확한 내용이다. <리스트 1>에는 스레드 우선순위를 조작하는 함수들이 나와 있다. SetThreadPriority 함수는 hThread로 전달된 스레드의 우선 순위를 nPriority로 설정하는 역할을 한다. nPriority로는 <표 1>에 나와 있는 상수 값들을 전달할 수 있다. GetThreadPriority 함수를 사용하면 hThread로 전달된 스레드의 우선순위 값을 확인할 수 있다.
표 1 스레드 우선 순위 값
상수명 의미
THREAD_PRIORITY_TIME_CRITICAL 가장 높은 우선 순위보다 더 높은 우선 순위
THREAD_PRIORITY_HIGHEST 가장 높은 우선 순위
THREAD_PRIORITY_ABOVE_NORMAL 보통 보다 조금 높은 우선 순위
THREAD_PRIORITY_NORMAL 보통
THREAD_PRIORITY_BELOW_NORMAL 보통 보다 조금 낮은 우선 순위
THREAD_PRIORITY_LOWEST 가장 낮은 우선 순위
THREAD_PRIORITY_IDLE 가장 낮은 우선 순위보다 더 낮은 우선 순위리스트 1 스레드 우선순위 조절 함수 원형
BOOL WINAPI SetThreadPriority(HANDLE hThread, int nPriority);
int WINAPI GetThreadPriority(HANDLE hThread);윈도우 설계자들은 아마도 정말 많은 고민 끝에 다음 이렇게나 다양한 종류의 우선순위를 만들어 두었을 것이다. 하지만 우리에게는 사실상 거의 쓸모 없는 기능이다. 왜일까? 이건 앞서도 말했던 것처럼 상대적이기 때문이다. 이 상대적이라는 말은 THREAD_PRIORITY_IDLE을 지정할 경우에 THREAD_PRIORITY_LOWEST보다는 덜 스케줄링 되지만 THREAD_PRIORITY_LOWEST로 실행할 스레드 조차 없다면 THREAD_PRIORITY_IDLE로 지정한다고 하더라도 모든 CPU 자원을 쓸 수 있다는 의미다. <리스트 2>에 그러한 코드가 나와있다. 아무 일도 하지 않는 스레드를 하나 생성한 다음 해당 스레드의 우선 순위를 THREAD_PRIORITY_IDLE로 지정했다. 여러분의 컴퓨터에서 살펴보면 알겠지만 해당 스레드가 한 코어의 모든 자원을 소모하는 것을 볼 수 있을 것이다.
리스트 2 100% CPU 점유율을 보여주는 예제
ULONG CALLBACK DummyThread(PVOID)
{
for(;;)
{
// 처리해야 할 작업들
}
return 0;
}
int _tmain(int argc, _TCHAR* argv[])
{
HANDLE thread = CreateThread(NULL, 0, DummyThread, NULL, 0, NULL);
SetThreadPriority(thread, THREAD_PRIORITY_IDLE);
WaitForSingleObject(thread, INFINITE);
CloseHandle(thread);
return 0;
}윈도우가 스케줄러를 잘못 설계한 것일까? 아니다. 당연히 제대로 만들었다. 운영체제 입장에서는 사용할 수 있는 모든 리소스를 사용하는 것이 바람직하기 때문이다. 메모리가 4GB만큼 탑재돼 있다면 필요하다면 4GB를 모두 사용하는 것이, CPU가 3GHz라면 해당 클럭을 모두 빼곡히 실행할 명령어로 채워 넣는 것이 바람직하다는 의미다. 하지만 사용자 입장은 그렇지 않다. 3GHz의 CPU를 사면 좀 더 CPU가 헐렁하기를 바라고, 4GB의 램을 탑재했다면 한 1GB의 여유 공간이 있기를 바라는 게 사람 심리다. 또 그런 심리를 충족시켜야 하는 것이 우리가 만드는 프로그램들이다.
그래서 현실세계에서 필요한 우선순위는 상대적인 것이 아니다. 절대적인 우선순위가 필요하다. “우리 제품은 2GHz 싱글 코어 CPU에서 초당 2%이상 CPU를 점유하지는 않습니다.”라는 이야기를 할 수 있는 우선순위가 필요하다는 말이다. 안타깝게도 윈도우에서는 그런 것들을 자동으로 해주지 않는다. 우리가 할 수 있는 유일한 방법은 저러한 for 루프마다 CPU 점유율을 계산해서 스레드가 자동으로 쉬도록 만들어주는 것 외에는 없다. 어떻게? Sleep이나 Wait계열의 함수를 호출해서 대기하는 수 밖에는 없다. 내지는 마스터 스레드가 개별 스레드의 동작을 모니터링하면서 Suspend/Resume 시키는 수 밖에는 없다.
스레드 친화도 (Thread Affinity Mask)
스레드 친화도란 스레드가 어느 CPU에서 스케줄링 될지를 결정하는 값이다. 친화도는 32비트 정수로 표현되며, 개별 비트가 하나의 CPU를 의미한다. 특정 비트가 1이면 해당 CPU에서 스레드가 실행될 수 있음을, 0이면 해당 CPU에서 스레드가 실행될 수 없음을 나타낸다. Process Hacker를 통해서 특정 스레드의 친화도를 설정하는 과정이 <화면 1>에 나와 있다. 살펴보면 해당 스레드는 현재 “CPU 1”만 비트가 켜져 있기 때문에 친화도 값은 2가 된다.
화면 1 작업관리자 프로세스 친화도 설정 화면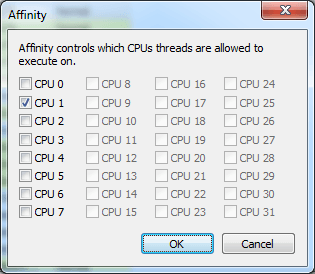
윈도우는 스레드와 프로세스에 대해서 개별적으로 친화도 값을 관리한다. 즉, 스레드 친화도 값과는 독립적으로 프로세스 친화도 값이 존재한다는 의미다. 스레드 친화도는 항상 프로세스 친화도의 서브셋이어야 한다. CPU가 4개인 컴퓨터를 생각해보자. 해당 컴퓨터에서 특정 프로세스의 친화도 값이 3이라면 해당 프로세스는 0, 1번 CPU에서만 수행될 수 있음을 의미한다. 이 때 해당 프로세스에 속한 스레드의 친화도 값은 2, 3번 CPU와 관계된 값을 지정할 수 없다. 해당 값을 지정하려고 하면 운영체제에서 오류를 리턴한다. 만약 스레드의 친화도를 2, 3번 CPU와 관계된 값으로 변경하고 싶다면 프로세스 친화도를 먼저 변경한 다음 스레드 친화도를 변경해야 한다.
스레드와 프로세스의 친화도 값을 설정하는 함수들이 <리스트 3>에 나와 있다. SetThreadAffinityMask 함수의 첫 번째 인자로 친화도를 설정할 스레드를, 두 번째 인자로 친화도 값을 지정하면 해당 스레드의 친화도를 지정된 값으로 변경한다. 리턴 값은 이전 친화도 값이다. 실패하면 0이 리턴된다. SetProcessAffinityMask 함수도 사용 방법은 동일하다. 단지 스레드가 아닌 프로세스에 대한 친화도를 설정한다는 차이만 있다. GetProcessAffinityMask 함수는 특정 프로세스의 친화도 값을 구하는 역할을 한다. hProcess로 친화도를 구할 프로세스 핸들을 전달하면 lpProcessAffinityMask로 해당 프로세스의 친화도 값이, lpSystemAffinityMask로는 시스템 친화도 값이 리턴된다.
리스트 3 스레드 친화도 설정 함수 원형
DWORD_PTR WINAPI SetThreadAffinityMask(
HANDLE hThread
, DWORD_PTR dwThreadAffinityMask
);
BOOL WINAPI SetProcessAffinityMask(
HANDLE hProcess
, DWORD_PTR dwProcessAffinityMask
);
BOOL WINAPI GetProcessAffinityMask(
HANDLE hProcess
, PDWORD_PTR lpProcessAffinityMask
, PDWORD_PTR lpSystemAffinityMask
);<리스트 4>에는 친화도를 설정하는 간단한 프로그램이 나와 있다. 듀얼코어 이상인 시스템에서 해당 프로그램을 실행하면 <화면 2>에 나타난 것과 같은 출력을 볼 수 있다. 친화도를 설정하기 전에는 해당 스레드가 여러 CPU에서 번갈아 가면서 실행되지만, 친화도를 2로 고정한 다음부터는 1번 CPU에서만 실행되는 것을 볼 수 있다.
리스트 4 스레드 친화도 변경 예제
ULONG
CALLBACK
ThreadProc(PVOID)
{
for(int i=0; i<10; ++i)
{
printf("%d\n", GetCurrentProcessorNumber());
Sleep(100);
}
printf("스레드 친화도 변경\n");
SetThreadAffinityMask(GetCurrentThread(), 2);
for(int i=0; i<10; ++i)
{
printf("%d\n", GetCurrentProcessorNumber());
Sleep(100);
}
return 0;
}
int main()
{
HANDLE thread = CreateThread(NULL, 0, ThreadProc, NULL, 0, NULL);
if(thread)
{
WaitForSingleObject(thread, INFINITE);
CloseHandle(thread);
}
return 0;
}화면 2 스레드 친화도 프로그램 실행 결과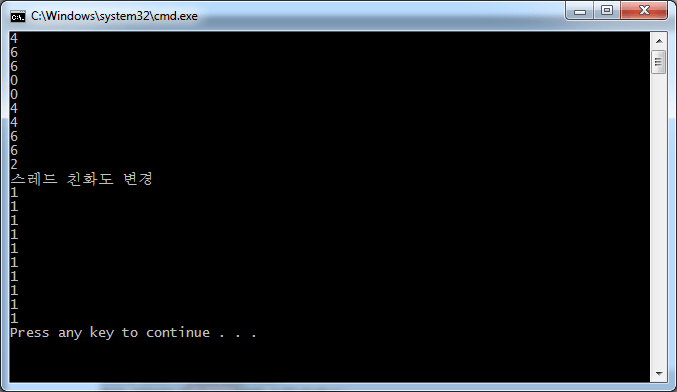
그렇다면 이러한 친화도 값은 언제 사용할까? 윈도우 사용자들은 최적화를 위해서 친화도 값을 많이 사용한다. 방송을 하는 게이머들은 게임을 특정 CPU에 바인딩 시키고, 분리된 CPU에 방송 프로그램을 할당하는 방법을 사용한다. 일부 게임 최적화 유틸리티는 이러한 작업들을 자동으로 해주기도 한다. 물론 이 경우에 진짜 최적화가 될지는 조금 생각을 해보아야 한다.
프로그래머가 친화도를 설정하는 경우도 크게 다르지는 않다. 프로그래머의 경우 자신이 작성한 프로그램의 스레드 구조를 완벽하게 알 수 있기 때문에, 병렬적으로 수행되어야 하는 스레드들에 대해서는 독립된 CPU를 설정함으로써 상호 컨텍스트 스위칭을 줄일 수 있다. IOCP도 그러한 식으로 최적화를 수행한 예로 생각할 수 있다.
스레드 친화도 값은 최적화 작업 외에도 CPU와 관련된 특수한 작업을 하기 위해서 사용하는 경우도 있다. QueryPerformanceCounter 함수가 대표적이다. 해당 함수는 윈도우의 고해상도 타이머 값을 가져오는 역할을 한다. 이 함수는 CPU의 클럭과 밀접한 관련이 있는데 일반적인 경우에는 멀티 프로세서 환경에서 어떤 프로세서에서 호출되는지에 관계없이 정상적으로 동작하지만 BIOS에 버그가 있는 경우에는 호출되는 프로세서에 따라서 다른 값이 리턴되는 경우가 있다. 이러한 버그를 보정하기 위해서 SetThreadAffinityMask가 사용되기도 한다.
<리스트 5>에 특정 코드의 수행 시간을 구하기 위한 전형적인 QueryPerformanceCounter 호출 구조가 나와 있다. 보통의 경우에 이 코드는 전혀 문제가 없지만 BIOS 등에서 처리가 잘못된 경우에는 1번 코드가 실행되는 프로세서와 2번 코드가 실행되는 프로세서가 다를 경우에 전혀 엉뚱한 두 값이 리턴되기도 한다. 이러한 부작용을 보정하기 위해서는 <리스트 6>에 나타난 것과 같이 SetThreadAffinityMask 함수를 사용해서 QueryPerformanceCounter 함수가 하나의 프로세서에서만 호출되도록 만들어주어야 한다.
리스트 5 QueryPeroformanceCounter 호출 예제
QueryPerformanceCounter(); // … 1
특정 작업들
QueryPerformanceCounter(); // … 2리스트 6 QueryPerformanceCounter 함수가 특정 프로세서에서 호출되도록 지정한 예제
SetThreadAffinityMask(GetCurrentThread(), 1);
QueryPerformanceCounter(); // … 1
특정 작업들
QueryPerformanceCounter(); // … 2앞서 스레드와는 별개로 프로세스 친화도 값이 있고, 스레드 친화도는 프로세스 친화도의 서브셋이 되어야 한다고 이야기했다. 이런 관점에서 살펴보면 <리스트 6>와 같은 코드는 문제가 있다. 상수 1을 지정해서 0번 CPU에서만 실행하겠다고 지정했지만, 현재 실행되는 프로세스가 0번 CPU에서 실행되지 않도록 설정됐을 수 있기 때문이다. 이런 경우를 좀 더 유연하게 처리하기 위해서는 현재 프로세스의 친화도 값을 구해서 비교하는 약간 복잡한 과정을 거쳐야 한다. <리스트 7>에는 이런 경우에 사용할 수 있는 간단한 헬퍼 클래스가 나와있다. 해당 객체를 생성하면 생성된 블록은 싱글 코어로 동작하게 만들어준다. <리스트 8>에는 SingleCore 클래스를 사용해서 QueryPerformanceCounter의 동작을 보정하는 방법이 나와 있다.
리스트 7 SingleCore 스레드
class SingleCore
{
public:
class SingleCoreError
{
};
ULONG_PTR oam_;
SingleCore()
{
ULONG_PTR pam, sam;
if(!GetProcessAffinityMask(GetCurrentProcess(), &pam, &sam))
throw SingleCoreError();
ULONG_PTR am = 1;
int bits = CHAR_BIT * sizeof(am);
for(int i=0; i<bits; ++i)
{
if(am & pam)
{
oam_ = SetThreadAffinityMask(GetCurrentThread(), am);
if(!oam_)
throw SingleCoreError();
break;
}
am <<= 1;
}
}
~SingleCore()
{
SetThreadAffinityMask(GetCurrentThread(), oam_);
}
};리스트 8 SingleCore 클래스를 사용해서 QueryPerformanceCounter 동작을 보정한 예제
SingleCore s;
QueryPerformanceCounter(); // … 1
특정 작업들
QueryPerformanceCounter(); // … 2스레드 지역 저장소(Thread Local Sotrage)
GetLastError는 SetLastError로 설정된 오류 코드를 리턴해 주는 기능을 하는 윈도우 함수다. 신입 개발자에게 해당 함수를 직접 구현해 보라고 시키면 <리스트 9>에 있는 코드와 같이 구현하는 경우가 많다. 이 코드는 기본적인 Set/GetLastError의 기능을 구현했지만 Set/GetLastError 함수가 스레드별로 독립적으로 오류코드를 관리되는 특징은 구현하지 않았다.
리스트 9 Set/GetLastError 구현 1
ULONG error_code = 0;
void MySetLastError(ULONG code)
{
error_code = code;
}
ULONG MyGetLastError()
{
return error_code;
}원본 함수와의 차이점을 살펴보기 위해서 <리스트 10>과 같은 프로그램을 만들어볼 수 있다. 두 개의 스레드를 만들어서 교차로 SetLastError, GetLastError를 호출하는 것이다. 이렇게 호출하면 원본 윈도우 함수와 우리가 구현한 버전의 차이를 발견할 수 있다. <리스트 10>의 코드에서 MySetLastError, MyGetLastError 호출 부분을 우리가 작성한 버전과 윈도우 표준 함수로 변경해 가면서 결과를 관찰해 보도록 하자. <화면 3>에는 윈도우 버전을 호출해서 결과를 출력한 화면이, <화면 4>에는 우리가 구현한 버전을 호출해서 결과를 출력한 화면이 나와있다. 살펴보면 윈도우 버전을 호출했을 때에는 스레드별로 독립적으로 오류코드가 관리되고 있는 것을 볼 수 있다. 반면 MySetLastError, MyGetLastError를 호출했을 때에는 GetLastError를 호출 했을 때 다른 스레드가 덮어쓴 값이 반환되는 것을 볼 수 있다.
리스트 10 MySet/GetLastError 테스트 프로그램
ULONG CALLBACK GleTestThread(PVOID)
{
ULONG code;
for(int i=0; i<2; ++i)
{
code = GetTickCount() % 100;;
printf("%d] SetLastError %d\n", GetCurrentThreadId(), code);
MySetLastError(code);
Sleep(1000);
printf("%d] GetLastError %d\n", GetCurrentThreadId(), MyGetLastError());
}
return 0;
}
int _tmain(int argc, _TCHAR* argv[])
{
HANDLE threads[2];
for(int i=0; i<ARRAYSIZE(threads); ++i)
{
threads[i] = CreateThread(NULL, 0, GleTestThread, NULL, 0, NULL);
Sleep(100);
}
WaitForMultipleObjects(ARRAYSIZE(threads), threads, TRUE, INFINITE);
for(int i=0; i<ARRAYSIZE(threads); ++i)
{
CloseHandle(threads[i]);
}
return 0;
}화면 3 Set/GetLastError 출력 결과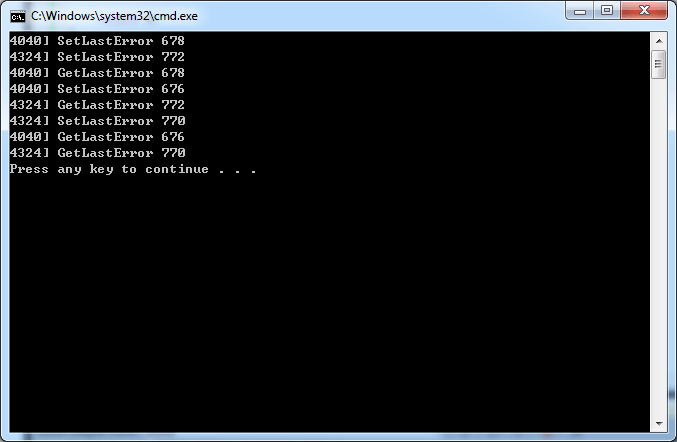
화면 4 MySet/GetLastError 출력 결과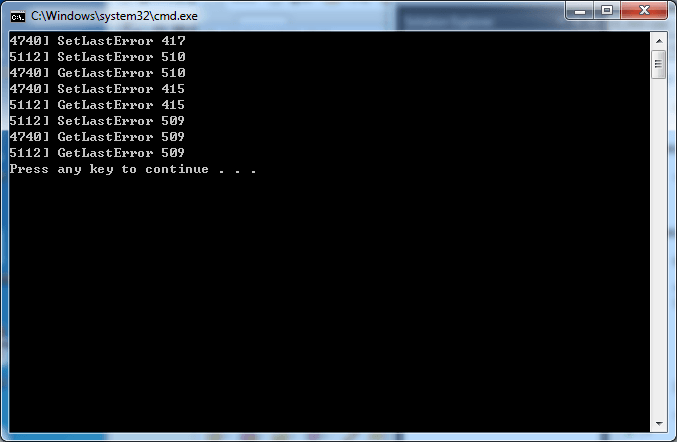
이러한 Set/GetLastError 함수의 특성을 이야기해 주면 똑똑한 신입 개발자들은 <리스트 11>과 같은 코드를 작성한다. 스레드와 오류코드를 연결하는 맵을 만들어서 관리하는 것이다. 물론 이 코드는 멸티스레드 환경에서 사용하기에는 조금 부적절한 버전이다. 더 똑똑한 개발자는 여기에 동기화 처리를 덧붙여서 <리스트 12>에 나와 있는 것처럼 실제로 써먹을 수 있는 코드를 만든다. 이쯤 되면 이제 기능적으로는 Set/GetLastError와 동일하다고 할 수 있다.
리스트 11 Map을 사용한 Set/GetLastError 구현
#include <map>
typedef std::map ErrorCodeMap;
typedef std::map::iterator ErrorCodeMit;
ErrorCodeMap error \_codes;
void
MyThreadSetLastError(ULONG code)
{
ULONG tid = GetCurrentThreadId();
ErrorCodeMit it = error \_codes.find(tid);
if (it == error \_codes.end())
{
error \_codes.insert(std::make\_pair(tid, code));
}
else
{
it->second = code;
}
}
ULONG
MyThreadGetLastError()
{
ULONG tid = GetCurrentThreadId();
ErrorCodeMit it = error \_codes.find(tid);
if (it == error \_codes.end())
{
return 0;
}
else
{
return it->second;
}
}리스트 12 동기화 처리를 추가한 Set/GetLastError 구현
CRITICAL_SECTION gle_cs;
void InitSystem()
{
InitializeCriticalSection(&gle_cs);
}
void CleanupSystem()
{
DeleteCriticalSection(&gle_cs);
}
void SyncMyThreadSetLastError(ULONG code)
{
EnterCriticalSection(&gle_cs);
MyThreadSetLastError(code);
LeaveCriticalSection(&gle_cs);
}
ULONG SyncMyThreadGetLastError()
{
ULONG ge;
EnterCriticalSection(&gle_cs);
ge = MyThreadGetLastError(code);
LeaveCriticalSection(&gle_cs);
return ge;
}이 모든 구현을 마치고 나면 한가지 의문이 떠오른다. 과연 이 방법뿐일까? 스레드별로 다른 저장소를 구현하기 위해서 우리는 매번 스레드와 자료를 연결하는 맵을 만들고 또 그 맵에 접근하기 위한 동기화 객체를 만들어야 할까? 구현의 번잡함을 차치하고서도 이 코드의 더 큰 문제점은 성능에 있다. 우리가 사용하려는 데이터의 논리적 특성은 전혀 공유적인 속성이 아니다. 하지만 우리는 구현상의 이유로 동기화 객체를 사용해서 직렬화를 시켰다. 이 말은 다시 표현하면 멀티 코어의 장점을 하나도 살리지 못한다는 의미가 된다.
윈도우는 앞서 제기된 문제를 해결하기 위해서 스레드 지역 저장소(Thread Local Storage)라는 것을 제공해 준다. 이름에서 알 수 있듯이 지금까지 우리가 논의했던 모든 문제들을 한번에 해결해주는 기능이라고 생각하면 되겠다. 스레드 지역 저장소를 통해서 우리는 스레드별로 별도의 데이터를 동기화 객체 없이 저장하고 읽어올 수 있다.
우선 스레드 지역 저장소를 조작하는 함수들을 살펴보자. <리스트 13>에 TLS 조작 함수들의 원형이 나와 있다. TlsAlloc 함수는 스레드 별로 관리할 데이터의 인덱스를 할당하는 역할을 하는 함수다. 해당 함수를 호출하면 사용할 수 있는 TLS 인덱스를 반환해 준다. TlsFree 함수는 dwTlsIndex로 지정된 인덱스를 해제하는 역할을 한다. TlsGetValue 함수는 dwTlsIndex로 전달된 인덱스에 해당하는 값을 반환하는 역할을 한다. TlsSetValue 함수는 dwTlsIndex로 전달된 인덱스에 해당하는 값을 lpTlsValue로 설정하는 역할을 한다.
리스트 13 TLS 조작 함수
DWORD WINAPI TlsAlloc(void);
BOOL WINAPI TlsFree(DWORD dwTlsIndex);
LPVOID WINAPI TlsGetValue(DWORD dwTlsIndex);
BOOL WINAPI TlsSetValue(DWORD dwTlsIndex, LPVOID lpTlsValue);여기까지 설명만 듣고는 어떻게 TLS가 우리가 제기했던 문제를 해결하는지 감이 잘 잡히지 않는다. 감을 잡기 위해서는 TLS의 구조에 대해서 알아야 한다. TLS가 동작하는 기본 원리는 운영체제가 스레드를 생성할 때에 스레드 스택을 만드는 것과 동일하게 TLS를 저장할 배열도 같이 만든다는데 있다. 물론 그 크기는 고정적이다. TLS로 할당할 수 있는 인덱스 개수는 그 배열의 개수만큼으로 한정된다. 이렇게 생성된 배열은 스레드의 컨텍스트 정보를 저장하는 곳에 기록돼서 스레드가 변경될 때마다 스레드가 생성될 때 같이 만들어진 TLS 배열을 가리키도록 설정된다. 따라서 우리는 표면적으로는 동일한 2번 인덱스의 값을 참조하지만 그걸 저장하고 있는 배열이 활성되는 스레드 컨텍스트에 따라서 변경되기 때문에 최종적으로는 다른 장조를 참조하게 되는 것이다.
<리스트 14>에는 이렇게 TLS 함수를 사용해서 Set/GetLastError를 구현한 버전이 나와있다. 앞서 작성한 것보다 코드도 훨씬 적지만 동기화 객체가 없기 때문에 멀티 코어의 장점도 십분 활용할 수 있다는 특징이 있다. 이렇게 직접 TLS 함수를 호출하지 않고도 __declspec(thread) 지시어를 사용하면 <리스트 15>에 나타난 것처럼 간단하게 TLS를 사용할 수 있다.
리스트 14 동적 TLS를 사용한 Set/GetLastError 구현
ULONG gle_index;
void InitSystem()
{
gle_index = TlsAlloc();
}
void CleanupSystem()
{
TlsFree(gle_index);
}
void MyTlsSetLastError(ULONG code)
{
TlsSetValue(gle_index, (LPVOID) code);
}
ULONG MyTlsGetLastError()
{
return (ULONG)(ULONG_PTR) TlsGetValue(gle_index);
}리스트 15 정적 TLS를 사용한 Set/GetLastError 구현
__declspec(thread) ULONG error_code = 0;
void MySetLastError(ULONG code)
{
error_code = code;
}
ULONG MyGetLastError()
{
return error_code;
}유저모드 APC
APC란 Asynchronous Procedure Calls의 약자로 우리말로 하면 비동기 프로시저 호출 정도로 번역할 수 있다. 여기서 가장 중요한 말은 제일 앞에 있는 비동기란 말이다. 우리가 일반적으로 호출하는 함수 구조를 동기 방식이라고 한다. 그렇다면 비동기 방식은 무엇일까? 바로 함수 호출이 즉시 일어나지 않고 지연돼 있다가 특정 시점에 호출된다는 의미다.
세부적인 내용을 살펴보기에 앞서 관련 함수들의 사용법에 대해서 먼저 알아보도록 하자. <리스트 16>에 유저모드 APC와 관련된 함수 원형들이 나와있다. 제일먼저 보이는 QueueUserAPC 함수가 APC 큐에 함수를 추가하는 역할을 한다. pfnAPC로는 수행될 APC 함수를, hThread로는 해당 APC 함수가 추가될 스레드 핸들을, dwData로는 pfnAPC 함수로 전달될 컨텍스트 변수를 지정하면 된다. APCProc은 실제로 수행될 APC 함수 원형이다. 리턴 값은 없으며, dwParam은 QueueUserAPC 함수에서 설정한 컨텍스트 변수가 전달된다. 그 다음으로는 SleepEx라는 함수가 있다. 해당 함수는 Sleep과 동일한 기능을 하는데 추가적인 기능은 두 번째 파라미터인 bAlertable 값을 통해서 스레드를 통지 가능 상태로 만들 수 있다는 점이 특징적이다.
리스트 16 유저모드 APC 관련 함수 원형
DWORD WINAPI QueueUserAPC(PAPCFUNC pfnAPC, HANDLE hThread, ULONG_PTR dwData);
VOID CALLBACK APCProc(ULONG_PTR dwParam);
DWORD WINAPI SleepEx(DWORD dwMilliseconds, BOOL bAlertable);이제 APC가 동작하는 세부 구조에 대해서 좀 살펴보자. 윈도우 스레드는 모두 APC 큐라는 것을 가지고 있다. 해당 큐에 값을 추가하는 함수가 QueueUserAPC 함수가 하는 역할이다. APC 큐에 추가된 함수들은 스레드가 통지 가능 상태(Alertable State)가 될 때에 일괄 수행된다. 스레드를 통지 가능 상태로 만드는 함수로는 SleepEx부터 WaitForSingleObjectEx, WaitForMultipleObjectsEx 등의 함수가 있다. 보통 스레드를 대기 상태로 만드는 함수의 Ex버전에 포함돼 있다고 생각하면 되겠다. 이렇게 스레드가 통지 가능 상태에 진입하면 윈도우는 APC 큐에 뭔가 추가된 것이 있거나 대기 중에 뭔가가 추가되면 해당 APC 루틴을 호출하고 대기를 종료한다.
<리스트 17>에는 이렇게 유저모드 APC루틴을 사용한 예가 나와 있다. 실행 결과에서도 볼 수 있지만 동기 호출과 다르게 APC 루틴의 가장 큰 장점은 APC 루틴이 추가된 스레드 컨텍스트에서 호출된다는 점이다. 따라서 특정 스레드 컨텍스트에서 특정 함수가 호출되도록 만들어야 하는 경우라면 유용하게 사용할 수 있다.
리스트 17 유저모드 APC 사용 예제
ULONG
CALLBACK
ApcThread(PVOID)
{
for(int i=0; i<3; ++i)
{
printf("통지 상태 시작\n");
SleepEx(1000, TRUE);
printf("통지 상태 끝\n");
for(int i=0; i<3; ++i)
{
printf("작업중...\n");
Sleep(1000);
}
}
return 0;
}
void
CALLBACK
ApcProc(ULONG_PTR)
{
printf("ApcProc %d\n", GetCurrentThreadId());
}
int main()
{
ApcProc(NULL);
HANDLE thread;
thread = CreateThread(NULL, 0, ApcThread, NULL, 0, NULL);
for(int i=0; i<10; ++i)
{
Sleep(1000);
QueueUserAPC(ApcProc, thread, NULL);
}
WaitForSingleObject(thread, INFINITE);
CloseHandle(thread);
return 0;
}
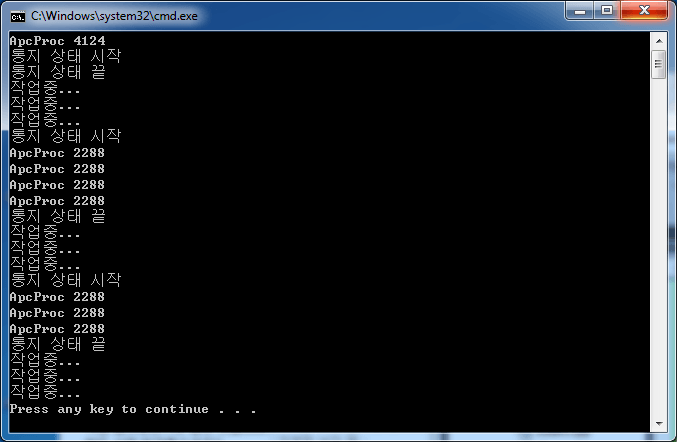
화면 5 유저모드 APC 사용 예제 실행 결과