<리스트 1>에 나와 있는 dec_counter라는 간단한 프로그램에서 이야기를 시작해보자. dec_counter 프로그램은 전역 변수 counter를 감소시키는 스레드를 생성하는 프로그램이다. 코드를 살펴보면 각 스레드는 DEC_LOOP_MAX 만큼 루프를 반복하면서 counter 값을 1씩 감소시키고, 주 스레드는 counter 값을 DEC_LOOP_MAX * DEC_THREAD_MAX로 초기화 한 후에, DEC_THREAD_MAX 개수만큼 감소시키는 스레드를 생성시켜서 동시에 실행되도록 만든다. 이렇게 했을 때 이론적으로는 모든 스레드의 실행이 완료되고 나면 counter 값은 0이 되어야 한다. 과연 그런지 dec_counter 프로그램을 컴파일해서 실행시켜 보도록 하자. 실행할 때에 주의해야 할 점은 반드시 컴파일 최적화 옵션을 꺼야 한다는 점이다. 최적화 옵션을 켜두면 컴파일러가 스레드 코드를 우리가 의도했던 것과는 다른 형태로 변형시키기 때문에 결과가 달라진다.
리스트 1 dec_counter 프로그램
#include <stdio.h>
#include <windows.h>
static const int DEC_THREAD_MAX = 1000;
static const int DEC_LOOP_MAX = 1000;
static int counter = 0;
ULONG
CALLBACK
DecCounter(PVOID)
{
for(int i=0; i<DEC_LOOP_MAX; ++i)
{
--counter;
}
return 0;
}
int _tmain()
{
HANDLE thread[DEC_THREAD_MAX];
for(;;)
{
counter = DEC_THREAD_MAX * DEC_LOOP_MAX;
for(int i=0; i<ARRAYSIZE(thread); ++i)
{
thread[i] = CreateThread(NULL
, 0
, DecCounter
, NULL
, CREATE_SUSPENDED
, NULL);
}
for(int i=0; i<ARRAYSIZE(thread); ++i)
{
ResumeThread(thread[i]);
}
for(int i=0; i<ARRAYSIZE(thread); ++i)
{
WaitForSingleObject(thread[i], INFINITE);
CloseHandle(thread[i]);
}
printf("DTM=%d, DLM=%d, counter=%d\n"
, DEC_THREAD_MAX
, DEC_LOOP_MAX
, counter);
getchar();
}
return 0;
}<화면 1>, <화면 2>, <화면 3>에는 DEC_THREAD_MAX와 DEC_LOOP_MAX를 변경해 가면서 프로그램을 실행한 결과가 나와 있다. 결과 화면에서 제일 먼저 눈에 띄는 사실은 우리의 예상과는 달리 counter 결과가 0이 아닌 경우도 있다는 점이다. 게다가 더 재미있는 점은 DEC_THREAD_MAX와 DEC_LOOP_MAX가 각각 1000과 1000일 때에는 프로그램 실행 중에도 그 때 그 때 결과가 달라지기도 한다는 것이다. 물론 이 모든 결과는 필자가 테스트한 컴퓨터에서의 결과일 뿐이고 여러분의 컴퓨터에서는 또 다른 결과가 나올지도 모른다.

화면 1 100×100 실행 결과
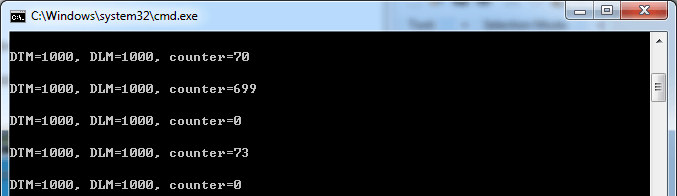
화면 2 1000×1000 실행 결과

화면 3 10×100000 실행 결과
 dec_counter 프로그램은 동기화 문제의 가장 큰 특징인 비결정론적인 성질을 잘 보여주고 있다. 비결정론적 성질이란 프로그램이 항상 동일하게 동작하는 것이 아니라 실행 환경에 따라서 동작이 달라지는 것을 말한다. 즉, 진짜로 프로그램이 그 때 그 때 다르게 동작한다는 말이다. 그래서 이런 성격의 동기화 문제는 재현하기도 쉽지 않을뿐더러 관찰하기는 더 어렵다. 이런 점 때문에 동기화 문제는 신입 개발자들에게 거짓말을 시키는 가장 대표적인 버그 중에 하나다.
dec_counter 프로그램은 동기화 문제의 가장 큰 특징인 비결정론적인 성질을 잘 보여주고 있다. 비결정론적 성질이란 프로그램이 항상 동일하게 동작하는 것이 아니라 실행 환경에 따라서 동작이 달라지는 것을 말한다. 즉, 진짜로 프로그램이 그 때 그 때 다르게 동작한다는 말이다. 그래서 이런 성격의 동기화 문제는 재현하기도 쉽지 않을뿐더러 관찰하기는 더 어렵다. 이런 점 때문에 동기화 문제는 신입 개발자들에게 거짓말을 시키는 가장 대표적인 버그 중에 하나다.
동기화 문제가 다루기 어려운 첫 번째 이유는 발생 확률이 낮아서 재현하기가 쉽지 않다는 점에 있다. 만약 여러분의 프로그램이 dec_counter 프로그램의 100×100 정도에 맞먹는 확률로 문제가 발생하는 코드를 가지고 있다면 아마 그 코드는 여러분의 QA팀 테스트 및 사내 테스트를 모두 무사히 통과할 것이다. 하지만 릴리즈하는 순간 고객들에게 프로그램이 정상적으로 동작하지 않는다는 이야기를 듣게 될 것이다. 고객의 클레임을 듣고 문재를 발생시키려고 시도해보아도 쉽지 않다. 왜냐하면 발생 확률이 극히 낮기 때문이다. 이런 어려움 때문에 고객 PC를 직접 디버깅하려고 한들 그것 또한 쉽지 않다. 고객 PC에서도 항상 100% 문제가 동일하게 발생하는 것은 아니기 때문이다.
동기화 문제가 어려운 두 번째 이유는 동기화 버그를 관찰하려는 시도 자체가 문제를 소멸시키는 성질을 가지고 있다는 점 때문이다. 동기화 문제는 가장 직접적인 디버깅 방법인 코드 트레이싱을 통해서는 문제 원인을 추적할 수 없으며, OutputDebugString 같은 아주 사소한 관찰 기법들이 코드에 추가되더라도 문제가 사라질 수도 있다. 실제로 dec_counter 프로그램의 ResumeThread 다음에 OutputDebugString이나 Sleep과 같은 구문을 넣게 되면 <화면 4>에 나타난 것처럼 문제가 사라진 것처럼 보여지게 만들기도 한다. 이런 이유 때문에 신입 개발자들은 곧잘 와서는 “OutputDebugString을 추가하니까 잘 됩니다”, 내지는 “Sleep을 좀 줬더니 버그가 사라졌습니다”같은 이야기를 하는 것이다. 사실 그건 버그를 사라지게 만든 것이 아니라 단순히 재현 확률을 낮췄을 뿐인데도 말이다. 천만 분의 일의 확률로 발생되는 문제를 억만 분의 일로 낮추어 본들 문제가 사라진 것은 아니다. 언젠가 어떤 환경에서 그 문제는 다시 발생할 수 있다.

화면 4 Sleep을 적용한 10×100000 실행 결과
그렇다면 이렇게 다루기 어려운 동기화 문제는 왜 발생하는 것일까? 또 이 문제를 해결하기 위한 방법들에는 어떤 것들이 있을까? 직접 만들지 않은 함수나 라이브러리가 잠재적으로 이런 동기화 문제가 발생할 수 있는지 없는지 사전에 알 수 있는 방법은 없을까? 지금부터 이 질문에 대한 해답을 찾아보도록 하자.
counter 값이 이상해진 이유
우리가 사용한 C 코드의 –counter라는 구문은 실제로 CPU 명령어로 번역되면 <리스트 2>에 나타난 것과 같이 3개의 명령어로 구성된다. 각 명령어는 counter가 저장된 메모리의 값을 레지스터로 복사하고, 레지스터 값을 1 감소 시키고, 그 감소된 값을 다시 counter가 저장된 메모리에 기록하는 일을 한다. <표 1>에는 counter 값이 2인 상황에서 세 개의 명령어를 두 개의 스레드에서 한 번씩 수행할 때에 실행 순서에 따라서 어떤 결과가 나타나는지가 나와 있다. 제일 먼저 나온 실행 순서가 우리가 일반적으로 생각하게 되는 순서다. 이 경우에는 당연히 결과는 우리가 예상한대로 0이 나온다. 반면 두 번째, 세 번째 실행 순서를 보면 실행 순서가 조금 바뀌었을 뿐인데 결과는 우리가 예상하지 않았던 1이 나오는 것을 볼 수 있다.
counter 값이 이상해진 이유도 바로 여기에 있다. <표 1>에 나타난 것과 같이 실행 순서가 일반적인 경우도 있고, 결과가 이상해지는 경우도 있는 것이다. 실행 순서가 모두 우리가 예상한 일반적인 실행 흐름과 100% 똑같다면 정상적인 결과가 나오게 되는 것이고, 조금이라도 달라졌다면 예측하지 못했던 결과가 나오게 되는 것이다.
리스트 2 –counter에 대한 어셈블리 명령어
mov ecx, dword ptr [counter]
sub ecx, 1
mov dword ptr [counter], ecx
mov ecx, dword ptr [counter]
sub ecx, 1
mov dword ptr [counter], ecx
---
counter = 0
mov ecx, dword ptr [counter]
mov ecx, dword ptr [counter]
sub ecx, 1
sub ecx, 1
mov dword ptr [counter], ecx
mov dword ptr [counter], ecx
---
counter = 1
mov ecx, dword ptr [counter]
sub ecx, 1
mov ecx, dword ptr [counter]
sub ecx, 1
mov dword ptr [counter], ecx
mov dword ptr [counter], ecx
---
counter = 1원자적 연산 (atomic operation)
앞서 우리는 –counter라는 구문이 실제로 어셈블리어로는 3개의 명령어로 구성돼 있고, 그 명령어의 실행 순서가 엉키면서 값의 상태가 이상해진다는 것을 배웠다. 그렇다면 3개의 명령어가 아닌 하나의 명령어로 만들면 문제가 사라지지 않을까? 이런 관점에서 동기화 문제에 접근하는 방식이 ‘원자적 연산’이다. 번역해 놓으니 단어가 좀 이상한데 ‘원자적 연산’이란 특정 연산이 한번에 수행된다는 의미를 가진다. 즉, 연산 수행 도중에 동일한 연산이 중첩돼서 실행될 수 없다는 것을 의미한다.
그렇다면 앞서 살펴본 3개의 어셈블리 명령어를 하나로 만들면 원자적 연산이 되는 것일까? 우리가 흔히 사용하는 인텔의 x86 CPU에는 –counter를 한번에 수행할 수 있는 dec라는 어셈블리 명령어가 존재한다. dec dword ptr [counter]와 같이 사용하면 위 3개의 명령어가 하는 일과 동일한 기능을 수행할 수 있다.
리스트 3 –counter를 하나의 인스트럭션으로 변경한 코드
ULONG CALLBACK DecCounter(PVOID)
{
for(int i=0; i<DEC_LOOP_MAX; ++i)
{
__asm dec dword ptr [counter]
}
return 0;
}<리스트 3>에는 이렇게 스레드 코드를 하나의 어셈블리 명령어로 고친 것이 나와 있다. 실행을 해보면 여러분의 시스템에 따라서 정상적이기도 하고 정상이 아니기도 한 현상이 발생할 것이다. 이 접근은 반쯤만 원자적인 방법이기 때문이다. 우리가 사용한 이 방법은 시스템이 싱글코어라면 원자성이 보장되지만 멀티코어라면 원자성이 보장되지 않는다. 멀티코어에서는 단일 명령인 dec 명령어 조차도 물리적으로 두 개 이상의 CPU에서 동시에 실행될 수 있기 때문이다. 참고로 멀티코어 환경에서 싱글코어와 동일한 상황의 테스트를 해보고 싶다면 dec_counter 프로그램에서 CreateThread 다음에 SetThreadAffinityMask 함수를 사용해서 모든 스레드가 한 CPU에서만 실행되도록 만들면 된다.
그렇다면 친화도를 조절하지 않고 멀티코어 환경에서 원자성을 보장할 수 있는 방법은 없을까? 물론 있다. 멀티코어 CPU를 설계한 사람들도 이러한 문제점을 충분히 알고 있었기 때문에 멀티코어 환경에서 원자성을 보장할 방법을 마련해 두었다. x86 CPU에서는 dec 명령어 앞에 lock을 붙여줌으로써 그런 일을 할 수 있다. <리스트 3>의 코드에 lock을 붙여서 컴파일하고 실행해보면 코어 개수에 상관 없이 어떠한 환경에서든 정상적으로 실행 결과가 나타나는 것을 볼 수 있다.
윈도우는 이러한 어셈블리 명령어를 손쉽게 사용할 수 있도록 원자성이 보장되는 API들을 만들어서 제공해 주고 있다. <표 2>에는 이러한 Interlocked 함수 중에서 자주 사용되는 함수들의 이름과 그 함수가 어떠한 동작을 한번에 하는지가 나와 있다.
표 2 자주사용하는 Interlocked 함수들
LONG __cdecl InterlockedExchange(
__inout LONG volatile *Target,
__in LONG Value
);
LONG Old = *Target;
*Target = Value;
return Old
///
LONG __cdecl InterlockedExchangeAdd(
__inout LONG volatile *Addend,
__in LONG Value
);
LONG Old = *Target;
*Target += Value;
return Old
///
LONG __cdecl InterlockedCompareExchange(
__inout LONG volatile *Destination,
__in LONG Exchange,
__in LONG Comparand
);
LONG Old = *Target;
if(*Target == Comparand)
*Target = Exchange;
return Old;
///
LONG __cdecl InterlockedDecrement(
__inout LONG volatile *Addend
);
++*Target;
return *Target
///
LONG __cdecl InterlockedIncrement(
__inout LONG volatile *Addend
);
--*Target;
return *Target바쁜 대기 (busy waiting)
동기화 이슈를 피하기 위한 다른 방법으로는 바쁜 대기가 있다. 바쁜 대기란 자신이 공유 데이터에 접근할 수 있는지를 수시로 체크하는 것을 말한다. <리스트 4>에는 DecCounter 스레드를 바쁜 대기를 사용해서 동기화 시킨 코드가 나와 있다. counter 변수 업데이트 전후로 can_update 값을 변경하고, counter 변수에 접근하기 전에 can_update가 접근 가능한 상태로 되어 있는지를 검사하고 있다. 이렇게 할 경우에 이론적으로는 동시에 하나의 스레드만 counter 변수 값을 변경할 수 있기 때문에 counter 값이 이상해지는 문제를 피할 수 있다.
리스트 4 바쁜 대기를 사용한 동기화
LONG can_update = TRUE;
ULONG CALLBACK DecCounter(PVOID)
{
for(int i=0; i<DEC_LOOP_MAX; ++i)
{
while(!can_update)
;
can_update = FALSE;
--counter;
can_update = TRUE;
}
return 0;
}<리스트 4>의 코드는 바쁜 대기의 기본적인 개념을 보여주기 위한 코드다. 실제로 해당 코드를 사용해서 스레드를 돌려보면 여전히 결과가 이상한 것을 볼 수 있는데 이는 바쁜 대기에 사용된 can_update 변수 조작에 원자적 연산이 사용되지 않았기 때문이다. <리스트 5>에는 원자적 연산을 이용해서 바쁜 대기를 완전하게 만든 코드가 나와 있다.
리스트 5 원자적 연산을 사용한 바쁜 대기
LONG can_update = TRUE;
ULONG CALLBACK DecCounter(PVOID)
{
for(int i=0; i<DEC_LOOP_MAX; ++i)
{
while(InterlockedCompareExchange(&can_update, FALSE, TRUE) != TRUE)
;
--counter;
InterlockedExchange(&can_update, TRUE);
}
return 0;
}dec_counter 프로그램의 경우에는 공유 자료에 접근하는 코드가 워낙 간단하고(–counter), 해당 연산 자체를 원자적 연산으로 바꾸는 것이 가능해서 바쁜 대기를 사용하는 의도가 불분명하지만 현실세계에서의 복잡한 연산을 단일화 하는 데에는 가장 손쉽고, 금방 떠오르는 방법이기 때문에 바쁜 대기는 의외로 자주 사용되기도 한다. 하지만 바쁜 대기는 멀티코어 환경이든 싱글코어 환경이든 프로그램이 의미 있는 코드를 수행하는데 보내는 시간보다 바쁜 대기를 위한 루프를 반복하는 곳에 CPU 자원을 더 많이 소모하게 된다는 치명적인 단점이 있기 때문에 가급적 사용하지 않는 것이 좋다.
잠금 (Lock)
동기화 문제를 해결하는 가장 일반적인 방법은 운영체제에서 지원하는 잠금 장치를 사용하는 것이다. 잠금 장치는 특정 코드 영역이 여러 곳에서 동시에 실행되지 않도록 만드는 일을 한다. 윈도우에서는 이런 목적을 위해서 크리티컬 섹션, 뮤텍스, 세마포와 같은 다양한 방법을 지원해준다. <리스트 6>에는 크리티컬 섹션을 사용해서 –counter가 한번에 하나의 스레드만 실행되도록 만든 코드가 나와 있다.
리스트 6 크리티컬 섹션을 사용한 동기화
CRITICAL_SECTION cs;
ULONG CALLBACK DecCounter(PVOID)
{
for(int i=0; i<DEC_LOOP_MAX; ++i)
{
EnterCriticalSection(&cs);
--counter;
LeaveCriticalSection(&cs);
}
return 0;
}잠금 장치의 경우에는 운영체제의 스케줄러와 밀접하게 연계되어 있다. 운영체제는 각 잠금 장치의 상태를 추적할 수 있기 때문에 특정 잠금 장치를 사용할 수 없는 상황에서 스레드가 해당 자원을 요청하면 요청한 스레드를 대기 상태로 만든다. 대기 상태로 만든다는 것은 해당 잠금 장치가 사용 가능해질 때까지 해당 스레드가 CPU 자원을 소모하지 않는다는 것을 의미한다. 이런 특징 때문에 바쁜 대기에서 살펴본 것과 같이 자원 획득을 위한 검사 루프에 CPU 자원이 소모하는 일이 없다.
그렇다면 잠금 장치를 사용하는 것이 모든 동기화 문제를 해결하는 가장 좋은 방법일까? 그렇지는 않다. 우선 잠금 장치는 특정 코드가 동시에 실행되는 것을 제한하는 기법이기 때문에 멀티코어의 성능을 해치는 결과를 초래한다. 즉, 잠금 장치가 많으면 많을수록 CPU 개수가 증가해도 얻을 수 있는 이득이 없다는 말이다.
윈도우 커널의 경우에도 내부적으로 디스패처 락이라는 전역 락이 존재한다. 커널 내부의 중요한 함수들은 모두 해당 락을 획득한 다음 작업을 진행하도록 되어 있는데 CPU 개수가 몇 개 안될 때는 문제가 되지 않았는데 CPU 개수가 늘어나면 늘어날수록 대부분의 스레드들이 디스패처 락을 획득하기 위해서 대기하는 상태로 노는 문제가 발생했다. Windows 7부터는 이런 문제점을 해결하기 위해서 디스패처 락의 구조를 변경했고, 그런 개선을 통해서 멀티코어에서의 가용성이 상당히 높아졌다고 한다.
최근에는 CPU 개수가 지속적으로 증가하는 추세이기 때문에 이러한 CPU 규모 가변성에 대응하기 위해서는 잠금 장치보다는 앞서 살펴본 원자적 연산을 사용한 무잠금 알고리즘들이 활발하게 개발되고 있다.
버퍼 분리
동기화 문제의 근본적인 원인은 여러 개의 스레드가 동일한 버퍼에 동시에 접근하려는 것에 있다. 지금까지 소개한 해결책은 모두 ‘동시에’라는 부분에 집중한 방법이었다. 반대로 ‘동일한’이란 말에 집중해서 동기화 문제를 해결할 수도 있다. 공유해서 접근하는 버퍼가 정말 공유되어야 하는 성질의 것인지에 대해서 다시 한번 생각해 보자는 것이다. 그리고 정말 공유할 필요가 없는 것이라면 그것을 분리함으로써 동기화 이슈를 완전히 제거할 수 있다.
<리스트 7>에는 srand, rand 함수의 일반적인 구현이 나와 있다. 코드를 살펴보면 두 함수 모두 전역 변수인 gseed 값을 갱신하는 것을 볼 수 있다. 따라서 이 구현은 다중 스레드에서 호출될 경우에 문제점이 있다고 할 수 있다. 왜냐하면 앞선 counter 예제와 똑같이 rand 함수 호출에 따라서 gseed 값이 불안정한 상태가 될 수 있기 때문이다.
리스트 7 일반적인 srand, rand 함수의 구현
static unsigned int gseed = 0;
void srand(unsigned int seed)
{
gseed = seed;
}
int rand(void)
{
return (((gseed = gseed * 214013L + 2531011L) >> 16) & 0x7fff);
}이러한 문제점을 해결하기 위해서는 앞서 언급했던 원자적 접근이나 잠금을 사용할 수 있다. 하지만 rand 함수의 구조를 살펴보면 사실 gseed 값은 전혀 스레드 별로 공유해야만 하는 성질의 것이 아님을 알 수 있다. 왜냐하면 완전히 독립적으로 움직이는 변수이기 때문이다.
따라서 이 경우에는 원자적 접근이나 잠금을 사용하는 것보다는 gseed라는 버퍼를 스레드 별로 분리하는 것이 좋은 방법이다. 그런 방법 중에 하나는 우리가 지난 연재에서 살펴보았던 스레드 지역 저장소가 있다. 스레드 지역 저장소를 사용하면 <리스트 7>의 코드를 거의 고치지 않고도 버퍼를 바로 분리할 수 있기 때문이다. 실제로 다양한 컴파일러에 포함된 멀티 스레드용 CRT 코드는 이러한 기법을 사용해서 srand와 rand 함수를 스레드 안전한 함수로 구현하고 있다.
스레드에 안전한 함수(Thread Safe Function)
동기화 문제가 점점 더 큰 이슈로 부각되면서 프로그래머 사이에는 동기화 이슈의 발생 가능성에 대해서 사전에 예고할 수 있는 장치가 필요했다. 그래서 나온 말이 ‘스레드에 안전한(Thread Safe)’라는 말이다. 스레드에 안전한 함수란 여러 개의 스레드에서 해당 함수를 무작위적으로 마구 호출해도 전혀 문제가 되지 않는 함수를 말한다. 반대로 스레드에 안전하지 않은 함수란 두 개 이상의 스레드에서 호출하면 부작용이 발생할 수 있는 함수를 의미한다.
일반적으로 요즘은 멀티 스레드 환경이 일반적이기 때문에 별다른 주의가 없으면 대부분의 함수는 스레드에 안전한 것으로 간주된다. 자신이 작성한 함수가 스레드에 안전하지 않고, 다른 개발자가 사용할 가능성도 있다면 관련 문서에 해당 함수가 스레드에 안전하지 않다는 내용을 표시해 주는 것이 좋겠다.
새롭게 제작되는 함수라면 가급적 인터페이스를 스레드에 안전하게 만드는 것이 좋다. 앞서 <리스트 7>에서 살펴본 rand 함수의 구현은 스레드에 안전하지 않은 함수였다. 그것을 대부분의 CRT에서는 스레드 지역 저장소를 사용해서 스레드에 안전한 함수로 제작한다는 것도 배웠다. CRT에서 스레드 지역 저장소를 사용한 이유는 rand 함수의 프로토타입을 변경할 수 없기 때문이다. 만약 rand 함수의 프로토타입을 변경할 수 있다면 <리스트 8>과 같이 전역 변수에 대한 의존성 자체를 제거해서 스레드에 안전한 함수로 만드는 것이 좋다.
리스트 8 스레드에 안전한 rand 함수
int rand(int *seed)
{
*seed = *seed * 214013L + 2531011L;
return ((*seed >> 16) & 0x7fff);
}재진입 가능한 함수(Reentrant Function)
끝으로 재진입 가능한 함수에 대해서 알아보자. 재진입이라는 말은 말 그대로 함수 내부로 다시 진입하는 것을 의미한다. ‘다시’라는 말이 의미하듯이 함수 코드가 처리되는 와중에도 다시 함수 내부로 진입됨을 의미한다.
윈도우 프로시저는 흔히 재진입 가능한 함수라고 표현된다. 이 내용을 보통 신입 개발자들은 <리스트 9>와 같은 간단한 메시지 처리 루틴에서 WM_PAINT 메시지가 처리되는 동안 Sleep 상태일 때에도 키보드가 눌리면 다시 MyWindowProcedure가 실행되어 WM_KEYDOWN 이벤트가 처리되는 것이라고 생각한다.
리스트 9 간단한 메시지 처리 루틴
LRESULT CALLBACK MyWindowProcedure(HWND Window, UINT MsgId, WPARAM W, LPARAM L)
{
switch(MsgId)
{
case WM_PAINT: Sleep(1000); break;
case WM_KEYDOWN: OutputDebugStringA("WM_KEYDOWN"); break;
}
return DefWindowProc(Window, MsgId, W, L);
}하지만 이는 잘못된 생각이다. 실제로 테스트해 보면 알겠지만 Sleep 상태인 동안에 키를 아무리 눌러본들 디버그 메시지는 출력되지 않는다. 이유는 무엇일까? 답은 메시지를 처리하는 방법에 있다. 일반적으로 많은 윈도우 개발 입문서에서 메시지 프로시저를 운영체제가 알아서 호출해 주는 것처럼 설명하지만 실제로 운영체제는 메시지 프로시저를 호출하는 일은 하지 않는다. 해당 일은 <리스트 10>에 나타난 것과 같은 메시지 처리 루틴에 의해 이뤄진다. DispatchMessage 함수 내부에서 해당 윈도우에 맞는 메시지 프로시저를 찾아서 호출되는 일이 진행된다. 따라서 해당 메시지 처리가 완료되어서 다음 GetMessage가 호출되기 전까지 메시지 프로시저는 새로운 것을 처리하고 싶어도 할 수 없는 상태인 것이다.
리스트 10 메시지 처리 루틴
while(GetMessage(&Msg, NULL, 0, 0))
{
TranslateMessage(&Msg);
DispatchMessage(&Msg);
}재진입이란 말이 실제로 하고자 했던 이야기는 윈도우 프로시저는 스레드에 안전하며 병렬적으로 호출이 가능하도록 작성되어야 한다는 것을 나타낸다. <리스트 11>과 <리스트 12>를 보면 무슨 의미인지가 분명해진다. <리스트 11>의 코드는 한 스레드에서 윈도우가 실행될 때와 두 스레드에 윈도우가 실행될 때 동작이 달라진다. 윈도우 의존적으로 처리되어야 하는 데이터가 정적 변수로 되어 있어서 다른 윈도우의 동작에까지 영향을 미치기 때문이다. <리스트 12>의 코드는 윈도우 프로시저가 글로벌 크리티컬 섹션에 묶여 있어서 한 스레드의 메시지가 처리되는 동안에 다른 스레드에서 생성한 윈도우는 함수 내부로 진입하지 못하는 문제가 발생한다. 서로 다른 스레드의 윈도우는 상호 동작에 간섭을 받지 않아야 함에도 이 메시지 프로시저는 한 스레드의 메시지 프로시저가 완료되기 전까지는 다른 스레드의 메시지 프로시저가 처리될 수 없게 됨으로써 서로 원활하게 동시 실행이 처리되지 못하는 문제가 있다는 것이다.
리스트 11 스레드에 안전하지 않은 메시지 프로시저
LRESULT CALLBACK MyWindowProcedure(HWND Window, UINT MsgId, WPARAM W, LPARAM L)
{
static int Count = 0;
switch(MsgId)
{
case WM_KEYDOWN:
++Count;
if(Count % 2)
OutputDebugStringA(“WM_KEYDOWN”);
break;
}
return DefWindowProc(Window, MsgId, W, L);
}리스트 12 병렬적으로 호출이 불가능한 메시지 프로시저
LRESULT CALLBACK MyWindowProcedure(HWND Window, UINT MsgId, WPARAM W, LPARAM L)
{
EnterCriticalSection(&GlobalCs);
switch(MsgId)
{
case WM_KEYDOWN: OutputDebugStringA(“WM_KEYDOWN”); break;
}
LeaveSection(&GlobalCs);
return DefWindowProc(Window, MsgId, W, L);
}재진입 가능한 함수란 <리스트 11>이나 <리스트 12>에 나타난 것과 같은 문제가 없어야 함을 말한다. 결국 이는 스레드에 안전한 함수보다 더 좁은 개념으로 기본적으로 스레드에 안전하면서 멀티 스레드 환경에서 잠금으로 인한 성능상의 이슈도 없어야 한다는 것을 의미한다.